Módulo 4 - Visualización y Procesamiento de Texto en la Terminal
Temas incluidos:
-
Visualizar contenido de archivos de texto (
cat,less,head,tail) -
Redirecciones de entrada/salida (
>,>>,<,2>,|) -
Uso de tuberías (pipes) para encadenar comandos
-
Búsqueda de texto dentro de archivos (
grepy familia) -
Búsqueda de archivos en el sistema (
find, usos básicos) -
Uso de editores de texto en terminal (introducción a
viy mención denano)
Visualizar contenido de archivos: cat, less, head, tail
Concepto desarrollado: Ahora que sabemos crear y manipular archivos, frecuentemente necesitaremos ver su contenido desde la línea de comandos, especialmente tratándose de archivos de texto como configuraciones o logs. Vimos cat (concatenate) brevemente: es la forma más simple de volcar el contenido de un archivo al terminal. Sin embargo, para archivos largos, cat no es práctico ya que mostrará todo de golpe. Ahí entran less (o su primo more), que permiten paginar y navegar. head y tail sirven para ver solo el comienzo o final de un archivo, respectivamente, útil para echar un vistazo rápido sin abrirlo completo.
-
cat: envía el contenido completo del archivo a la salida estándar (la pantalla). Si el archivo es corto, perfecto. Si es muy largo, inundará la pantalla y solo verás el final. Por eso, se suele combinar con| lessen caso de duda, o usar directamenteless. -
less: abre un visor interactivo de texto. No carga todo el archivo de golpe (es eficiente con archivos grandes), y te deja desplazarte con las flechas, PageUp/PageDown, inicio (g) y fin (G) del archivo, búsqueda (/textohacia adelante,?textohacia atrás). Para salir deless, pulsaq. Un dicho en Unix es: “less is more” (un juego de palabras, ya quelessreemplazó al antiguomore). -
head: muestra por defecto las primeras 10 líneas de un archivo. Con-npuedes especificar cuántas. Ej:head -n 20 archivo.txtmuestra primeras 20 líneas. -
tail: muestra las últimas 10 líneas por defecto. O con-n Xlas últimas X líneas. Muy útil para ver logs recientes. Además,tail -f archivo.log(follow) te permite ver en tiempo real lo que se añade al final del archivo (se queda “escuchando” nuevas líneas; presiona Ctrl+C para salir de ese modo). Esto es genial para monitorear un log mientras un servicio escribe en él, por ejemplo. -
Visualizar archivos binarios: Herramientas como
cat/lessasumen texto. Si intentas ver un archivo binario (ej. una imagen o un ejecutable), obtendrás caracteres raros. En esos casos, mejor no usarcat(puede incluso sonar el beep del terminal por caracteres de control) y preferir comandos específicos (por ejemplo,xxdpara ver hexdumps, o simplemente no abrir binarios en terminal).filecomo vimos te dice si es binario o texto, para decidir.
Comandos esenciales y sintaxis:
-
cat archivo.txt: muestra todo el contenido de archivo.txt. Si son pocas líneas, se verá en pantalla, si no, puedes hacer scroll hacia arriba en la terminal o preferirless. -
less archivo.txt: abre el visor interactivo. Dentro, usaj/ko flechas para bajar/subir línea a línea, PageDown/PageUp para saltos mayores,gpara inicio,Gpara fin,/para buscar. -
head -n 5 archivo.txt: muestra las primeras 5 líneas. Sin-n, muestra 10 por defecto. -
tail archivo.txt: muestra las últimas 10 líneas.tail -n 50 archivo.txtúltimas 50. -
tail -f archivo.log: sigue actualizando a medida que crece el archivo. Úsalo para ver “en vivo” la actividad. Puedes abrir otra terminal y generar actividad (por ejemplo, agregar líneas conecho "prueba" >> archivo.log) y verás aparecer esas líneas en la primera terminal con tail -f. -
Combinaciones útiles:
head archivo | tail -n 1te daría la 10ma línea (head da 10 primeras, pipe a tail toma la última de esas, resultando línea 10). Otail -n 20 archivo | head -n 5para obtener del 16 al 20 (últimas 20 y de esas las primeras 5). Hay comandos más directos para ciertas cosas, pero saber combinar head/tail es trucazo de concha.
🧪 Ejercicio práctico paso a paso:
-
Leer un archivo de configuración del sistema: Prueba con algo seguro, como
/etc/os-releasenuevamente. Ejecutacat /etc/os-release. Deberías ver el contenido completo (no es muy largo). Ahora conless:less /etc/os-release. Intenta buscar dentro de less la palabra "CentOS" con/CentOS. Si la encuentra, estará resaltada. Sal conq. -
Usar head y tail en archivos de log: Ve al directorio
/var/log(puedes hacerlo como usuario normal, muchos logs tienen permisos de lectura global). Por ejemplo, ejecutahead -n 5 /var/log/dnf.log(muestra las primeras 5 líneas del log de DNF, que registra instalaciones/actualizaciones). Luegotail -n 5 /var/log/dnf.logpara las últimas 5. Si ese archivo no existe o está vacío (posible si no se ha usado mucho dnf), prueba con otro log, comotail -n 20 /var/log/messages(si existe; en CentOS Stream 9, rsyslog puede no estar por defecto. Alternativamente,journalctl -n 20ver las últimas 20 entradas del journal; aunquejournalctles un comando especial de systemd que veremos en módulo de servicios). -
Monitorear en tiempo real (opcional): Abre dos terminales. En una, ejecuta
tail -f ~/proyectos/demo1/README.md(por ejemplo, un archivo de texto que tengas a mano). Luego, en la otra, edita ese archivo agregándole líneas (puedes hacerecho "Nueva línea" >> ~/proyectos/demo1/README.md). Observa cómo en la primera terminal, tail muestra inmediatamente la línea añadida. Esto simula ver un log creciendo. -
Combinar head y tail: Crea un archivo de varias líneas, por ejemplo:
seq 1 100 > numeros.txt(el comandoseqgenerará una secuencia del 1 al 100, redirigido a numeros.txt). Ahora, ¿cómo ver solo la línea 50 sin abrir todo? Puedes hacerhead -n 50 numeros.txt | tail -n 1. Prueba y deberías ver solo "50". Analiza por qué funcionó esa tubería. -
Entender límites de cat: Intenta
cat numeros.txt. Verás pasar 100 líneas rápidamente (aunque 100 no son tantas, prueba conseq 1 10000 > numeros2.txtycat numeros2.txtpara inundar la pantalla). Date cuenta cuándo prefieres usarlessen lugar decat.
Puntos clave a recordar:
-
cates rápido y útil para archivos cortos o concatenar varios archivos (por eso se llama concatenate). Puedes hacercat file1 file2 > combo.txtpara juntar archivos. Pero para lectura humana de archivos largos, mejor usar paginadores comoless. -
lessno edita, solo visualiza. A veces uno puede confundirlo con un editor porque navegas dentro. Si quieres editar, deberás abrir un editor real (veremosvimás adelante). -
head/tailte permiten muestrear partes de un archivo sin abrirlo todo. Muy usado para verificar logs (tail) o asegurarse de un formato al inicio (head).tail -fes indispensable para ver en vivo logs de servidores o procesos en ejecución. -
Todos estos comandos leen el archivo en texto plano. Si necesitas ver contenido binario, no fuerces con
cat/less. Un caso especial: log binario de journalctl (journal de systemd) se ve con su propio comandojournalctl, no intentescat /var/log/journal/...binarios. -
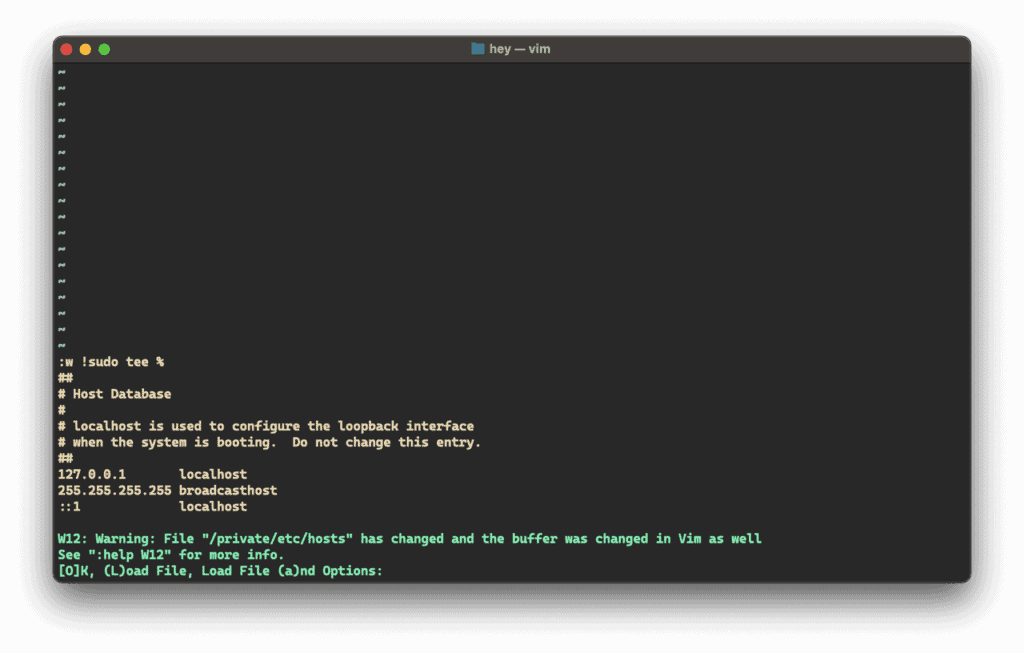
(Imagen sugerida: una captura de pantalla de un terminal usando
lesspara leer un archivo, mostrando cómo el texto se pagina y quizás resaltando una búsqueda. Esto ilustraría la interfaz delessy cómo se diferencia de simplemente imprimir todo concat.)** -
Recuerda que muchas de estas herramientas pueden trabajar con redirecciones/pipes: por ejemplo, puedes enviar la salida de un programa a
lesspara verla paginada, no solo archivos. Ej:dmesg | less(dmesg muestra mensajes del kernel, pagínalos con less para leer cómodo). Esto demuestra quelesspuede actuar tanto sobre archivos como sobre flujo de datos de un pipe.
Errores comunes y cómo evitarlos:
-
Usar
caten archivos gigantes: Ya se comentó, pero reiteramos: si el archivo tiene miles de líneas,catte “escupe” todo y solo verás el final. Evita frustrarte: mejor comienza conlessdirectamente. -
Confundir
headytailen sintaxis: A veces alguien escribehead 5 archivo.txt(sin -n). Esto en algunas versiones de head puede interpretarlo, pero la sintaxis formal requiere-n 5. Igualmente con tail. Otro error:tail -5 archivo(algunos SO lo aceptan, pero en otros -5 podría ser interpretado como opción obsoleta). Es mejor adherirse a la forma estándar-n. -
Olvidar salir de
lessotail -f: Si abreslessy te quedas esperando, recuerda que está en modo visualización; debes salir conq. Entail -f, hasta que no hagas Ctrl+C, no te devolverá el prompt. Si accidentalmente ejecutastail -fen un archivo que no cambia nunca, parecerá que la terminal se “colgó”, pero en realidad está esperando nuevas líneas. Solo debes interrumpirlo manualmente. -
No darse cuenta de permisos: Si intentas
less /var/log/securepor ejemplo (log de seguridad en CentOS) como usuario normal, te dirá “Permission denied” porque solo root puede verlo. No es un error del comando, sino de permisos del archivo. Solución: usarsudosi realmente necesitas verlo, o practicar con archivos a los que tengas acceso. -
Interpretar mal caracteres especiales en cat: Si un archivo tiene caracteres no imprimibles,
catpuede producir efectos raros (limpieza de pantalla, soniditos). Por ejemplo, mostrando un archivo con un bell character puede hacer sonar la campana del sistema. Si pasa algo extraño tras uncat, intenta ejecutarreset(restablece la terminal) o simplemente evita catar binarios.lesssuele representar caracteres raros como^@o notación<FF>para form feed, etc., haciéndolos evidentes.
Tips de rescate si algo falla:
-
Abrir múltiples archivos con less:
less archivo1 archivo2te deja ver varios uno tras otro. Dentro de less, usa:npara siguiente archivo,:ppara anterior. Esto es útil si quieres comparar varios archivos de texto sin salir del visor. -
Guardar salida en un archivo (redirección): Si
cat filemuestra en pantalla pero quisieras guardar esa salida (que en este caso es igual al archivo mismo), podrías redirigir a otro lado. Por ejemplo:head -n 100 log.txt > primer100lineas.txt. Esto captura esas líneas en un nuevo archivo. Tenlo en cuenta para extraer porciones de archivos. -
Ver numeración de líneas: Para ciertos análisis, puede interesar ver los números de línea junto al contenido.
nl archivo.txtmostrará el archivo con cada línea numerada.cat -n archivo.txthace algo similar (añade números). Útil en archivos grandes para referenciar posiciones. -
Color en grep/less: Si usas
grep --colorpodrás resaltar el término buscado en la salida. Por ejemplogrep --color -n "ERROR" /var/log/messages. Esto imprimirá coincidencias con "ERROR" resaltadas y con número de línea (-n). Y enless, si exportasLESS=Ro usasless -R, este puede preservar los códigos de color. Así podrías hacergrep --color=always "ERROR" archivo | less -Rpara buscar y leer con color. Son trucos para visualizar mejor resultados de búsqueda en texto. -
Fijarse en encoding: Si un archivo se ve con símbolos raros, puede tener un encoding distinto (UTF-16, etc.).
lessa veces detecta y advierte, pero puede mostrar mojibake (caracteres extraños). Conviértelo a UTF-8 si necesitas leerlo (usandoiconvpor ejemplo), o abre con un editor que soporte ese encoding.
Criterios de evaluación del módulo:
✅ El alumno maneja con soltura la visualización de archivos de texto: puede decidir correctamente cuándo usar cat vs less vs head/tail según el tamaño y lo que necesita ver.
✅ Sabe navegar en less y realizar búsquedas simples dentro del contenido, así como salir adecuadamente de las herramientas interactivas sin quedar “atrapado”.
✅ Aplica head y tail para obtener partes de archivos, e incluso los combina con tuberías para acceder a posiciones específicas o filtrar rápidamente contenido.
✅ Demuestra comprensión de qué ocurre al ver archivos en vivo con tail -f y puede describir un escenario donde eso sea útil (por ejemplo, monitorear el log de un servicio en tiempo real).
✅ Entiende que estas herramientas esperan archivos de texto plano, y en caso de archivos binarios saben verificar primero con file o usar herramientas especiales en vez de forzar la visualización en terminal.
❓ Preguntas de repaso recomendadas:
-
Tienes un archivo de 1000 líneas. ¿Qué comando usarías para ver, de forma paginada, el contenido completo a tu ritmo?
-
¿Cómo buscarías la palabra "ERROR" dentro de un archivo de registro usando la terminal? (Piensa en combinar dos conceptos: un comando para mostrar contenido y otro para filtrar).
-
¿Qué hace exactamente la opción
-fdetaily en qué casos la utilizarías? -
Si solo quieres ver las primeras 20 líneas de todos los archivos
.logen/var/log, ¿qué combinación de comandos podrías emplear? (Pista:headpuede procesar múltiples archivos y mostrar un encabezado con el nombre de cada uno). -
¿Cómo navegas hacia el final de un archivo abierto con
less? ¿Y cómo buscarías nuevamente la siguiente aparición de un término después de la primera búsqueda con/?
Requisitos previos al módulo:
-
Haber creado o disponer de algunos archivos de texto con contenido (puedes usar los generados en ejercicios previos, o archivos del sistema que tengas permiso de leer) para practicar visualización.
-
Conocimientos de módulos anteriores: navegación (
cd), listados (ls), redirecciones básicas (hemos empezado a usarlas aquí), manejo de terminal en general. -
Un entorno donde puedas abrir múltiples terminales a la vez (opcional) para probar
tail -fen vivo, o alternativamente habilidad para abrir una segunda sesión SSH si estás en un servidor. Esto es opcional pero enriquecedor para ciertas prácticas en tiempo real. -
Nota: Este módulo comienza a introducir redirecciones (
>,>>,|). Si algo de esto no quedó claro en la práctica, repasa los ejemplos y no dudes en experimentar en un entorno seguro (por ejemplo, redirigir la salida dels -R /etca un archivo en tu home para ver luego su contenido tranquilamente conless).
Redirecciones y tuberías: encadenando comandos
Concepto desarrollado: La verdadera potencia de la línea de comandos en Linux viene al encadenar comandos y redirigir flujos de información. Por defecto, cada comando tiene una entrada estándar (STDIN), una salida estándar (STDOUT) y una salida de error (STDERR). Normalmente, la entrada estándar es el teclado (lo que tipeas), la salida estándar es la pantalla (donde ves resultados), y la salida de error también la pantalla (donde ves mensajes de error). Con redirecciones, puedes cambiar esos destinos/orígenes.
-
>redirige la salida estándar de un comando a un archivo (sobrescribiéndolo). Ya lo usamos:echo "hola" > file.txttomó la salida de echo (que normalmente iría a pantalla) y la guardó en file.txt. -
>>anexa la salida al final de un archivo, sin sobrescribir lo existente. Ej:echo "mundo" >> file.txtagrega "mundo" al final de file.txt en una nueva línea. -
<toma la entrada estándar de un archivo, en lugar del teclado. Por ejemplo: si tienes un archivo de comandos, podrías hacerbash < script.shpara que bash lea comandos de ese archivo en lugar de esperar que los tipees (aunque normalmente usaríasbash script.shdirectamente, es solo un ejemplo). Otro ejemplo: algunos programas que esperan input del usuario podrían leer de un archivo con< archivo_de_respuestas. -
2>redirige la salida de error. Ej:comando 2> errores.txthará que cualquier mensaje de error que normalmente verías en pantalla se guarde en errores.txt, mientras que la salida normal sigue en pantalla. También existe2>>para anexar errores, y combinaciones como&>para redirigir tanto stdout como stderr juntos al mismo destino (por ejemplo,&> log.txt). -
Pipelines (
|): Permiten tomar la salida estándar de un comando y conectarla a la entrada estándar del siguiente comando. Así creas “tuberías” de procesamiento. Un ejemplo ya usado:ls -l /etc | grep ssh. Aquí,ls -l /etcgenera listado de /etc, en vez de ir a pantalla, la tubería lo pasa como entrada agrep ssh, que filtra solo líneas que contengan "ssh". Otro:ps aux | sort -nrk 3 | head– esto listaría procesos, los ordena (sort) numéricamente inverso por la columna 3 (uso de CPU) y luegoheadtoma los primeros (osea los 10 más altos en CPU). Esa pipeline te muestra los top 10 procesos por CPU.
Redireccionar te permite guardar resultados de comandos en archivos para revisarlos o procesarlos luego, y las tuberías te dejan combinar herramientas pequeñas para resolver tareas complejas de forma elegante, pasando datos de una a otra.
Comandos esenciales y sintaxis:
(Más que comandos, aquí resaltamos usos de operadores)
-
comando1 | comando2: pipe básico. Ej:cat grande.txt | less(manda texto de cat a less),dmesg | grep USB(filtra mensajes del kernel buscando “USB”). -
comando > archivo: redirigir salida a archivo (sobrescribe). Ej:ls /bin > listado_bin.txtguarda listado de /bin en _listadobin.txt. -
comando >> archivo: redirigir salida añadiéndola al final. Ej:date >> actividad.logagrega la fecha/hora actual a actividad.log, útil para logs personalizados. -
comando 2> errores.txt: guarda errores en errores.txt. Ej:find / -name "*.conf" 2> /dev/nullbusca archivos .conf desde raíz y silencia los errores de “Permiso denegado” enviándolos a /dev/null (un dispositivo especial que descarta todo lo que recibe, literalmente un basurero de datos). -
comando1 | comando2 | comando3: múltiples pipes encadenados. Ejemplo más complejo:cat datos.csv | awk -F, '{print $2,$5}' | sort | uniq -c > estadisticas.txt. Aquí estamos filtrando columnas 2 y 5 de un CSV, ordenando, contando únicos y guardando resultados. Lo importante es ver que se pueden encadenar varias etapas. -
Combinación STDOUT+STDERR:
comando &> todo.txt(Bash) ocomando > todo.txt 2>&1. Esto redirige ambas salidas (normal y error) al mismo archivo todo.txt. Útil para capturar todo la salida de un script o comando (por ejemplo, al depurar). -
Herencia de redirección: Si haces algo como
(comando1; comando2) > output.txt, ambas salidas de comando1 y 2 van a output.txt, porque se agruparon en subshell. Ocomando1 | tee archivo(tee explicado abajo) para mandar a pipe y archivo a la vez. -
Comando
tee: Este comando especial lee de entrada estándar y envía la salida a pantalla y a archivo simultáneamente. Por ejemplo:ls /etc | tee listado.txt | grep network. Esto mostrará en pantalla todo el listado (por tee), lo guardará en listado.txt, y además pasará la salida a grep para filtrar “network” (cuyo resultado final saldrá en pantalla). Útil cuando quieres ver la salida y guardarla a la vez.
🧪 Ejercicio práctico paso a paso:
-
Redirigir salida a archivo: Toma un comando cuyo resultado conozcas, por ejemplo
uname -a(información del kernel/SO). En lugar de verlo, guárdalo:uname -a > sistema.txt. No hay salida en pantalla si todo fue bien. Hazcat sistema.txtpara verificar que ahí está el texto con la info del sistema. -
Anexar vs sobrescribir: Escribe dos líneas en un archivo usando echo con redirección. Ej:
echo "Primera línea" > prueba.txt. Luegoecho "Segunda línea" >> prueba.txt. Ahora visualiza concat prueba.txty debería contener ambas en orden. Si hubieras usado>la segunda vez en lugar de>>, la primera línea se habría perdido (sobrescrita). -
Redirigir errores: Prueba a listar un directorio donde no tengas acceso para generar error, por ejemplo:
ls /root. Verás un error en pantalla "Permission denied". Ahora intentals /root 2> error.txt. No ves nada en pantalla; compruebacat error.txty ahí estará el mensaje de error. Haz un tercer experimento:ls /root > salida.txt 2> error.txt. Como ls /root no genera salida normal (solo error), salida.txt quedará vacío y error.txt contendrá el error. -
Usar pipes para filtrar: Veamos un caso real: ejecutar
ps -ete lista todos los procesos en formato simple. Suele ser muy largo. Úsalo con pipe:ps -e | wc -l. El comandowc -lcuenta líneas; así sabrás cuántos procesos hay en ejecución. Otro:df -h | grep "^/dev"– muestra espacio en disco (df -h) pero filtrando solo líneas que empiezan con /dev (es decir, omitirá tmpfs y demás, mostrando solo discos reales montados). Intenta tambiénmount | column -t | less(aquícolumn -ttoma la salida de mount y la tabula en columnas organizadas, muy útil para leer listados alineados). -
Pipe múltiple ejemplo: Combinemos varios:
ps aux | sort -rk 3 | head -n 5. Esto listará los 5 procesos top en uso de CPU (columna %CPU es la 3 en ps aux). Desglosando:ps auxlista procesos;sort -rk 3ordena reverso por col 3 (r=reverse, k=key campo 3);head -n 5toma los primeros 5. Ejecuta el comando y observa los resultados. -
Tee (opcional avanzado): Ejecuta
ip a | tee interfaces.txt | grep inet. Esto mostrará todas las líneas que contienen "inet" (direcciones IP asignadas) de los datos deip a, a la vez que guarda la salida completa deip aen interfaces.txt. Revisa el archivo para ver que tiene todo, mientras en pantalla quizás solo viste las filtradas por grep (porque después de tee, la tubería continuó a grep). -
Redirección de entrada: Crea un archivo pregunta.txt con una pregunta:
echo "¿Cuál es tu nombre?" > pregunta.txt. Ahora, un comando tonto:catsin argumentos leerá de entrada estándar (espera que le teclees algo para repetirlo). Si ejecutascat < pregunta.txt, en lugar de esperar teclado, cat tomará el contenido de pregunta.txt como si lo hubieras escrito tú. Verás en pantalla "¿Cuál es tu nombre?" (porque cat lo replicó). No es muy emocionante, pero demuestra<. Otro uso: algunos programas interactivos pueden llenarse de esta manera para automatizar input (aunque herramientas comoexpectexisten para casos complejos). -
Capturar stdout y stderr juntos: Haz un comando que genere tanto salida normal como error. Por ejemplo:
find /etc -maxdepth 1 -name "passwd" -printf "Encontrado: %p\n"(esto busca en /etc el archivo passwd con formato personalizado). Si lo haces normal, verás posiblemente un par de “Permission denied” si encuentra directorios sin permiso (aunque-maxdepth 1limita eso). Intenta:find /etc -maxdepth 1 -name "passwd" -printf "Encontrado: %p\n" &> find_output.txt. Luego examina _findoutput.txt concat. Debería contener la línea "Encontrado: /etc/passwd" y quizás errores si hubo, todo junto. Sin&>, hubieras necesitado redirigir 2 cosas por separado.
Puntos clave a recordar:
-
La redirección
>siempre sobrescribe el archivo de destino desde el inicio. Ten cuidado porque no hay confirmación. Un descuido clásico es hacer>al archivo equivocado y básicamente vaciarlo/reemplazarlo. Verifica dos veces la ruta después de>antes de ejecutar. -
Puedes encadenar tantos pipes como necesites. La filosofía Unix es construir soluciones uniendo programas pequeños que hacen una cosa bien. En lugar de buscar un mega-comando que todo lo resuelve, piensa en dividir el problema: ¿puedo obtener una lista de algo? (comando1), ¿cómo filtro/transformo esa lista? (comando2), etc., hasta lograr el resultado final.
-
/dev/null es tu amigo para descartar cosas que no te interesan. Si un comando es verboso en errores irrelevantes, redirígelos a /dev/null. Ej:
grep -R "foo" / 2>/dev/nullbuscaría "foo" en todos los archivos desde raíz, ignorando montones de errores de permiso. -
(Imagen sugerida: un esquema visual de tuberías y redirecciones: por ejemplo, iconos de comandos con flechas que representan la salida de uno entrando a otro, y hacia un archivo. Mostrar STDIN, STDOUT, STDERR con flechas a teclado/pantalla/archivos para ilustrar cómo
>2>y|reencaminan esos flujos. Esto ayuda a entender por dónde viajan los datos.)** -
Al usar pipes, cada comando corre concurrentemente en su propio proceso, y el shell conecta la salida de uno con la entrada del siguiente. Esto significa que, por ejemplo, en
comando1 | comando2, ambos pueden ejecutarse a la vez en flujo. A veces, con programas interactivosy pipes, puede haber situaciones de buffering (los datos se almacenan hasta cierto tamaño antes de pasarlos). En general no afectará nuestras tareas básicas, pero es bueno saber que la tubería conecta procesos vivos, no es secuencial linea-por-linea estrictamente sino flujo continuo. -
Redireccionar la entrada
<se ve menos que redireccionar salida, pero es útil en contextos de automatización. Un comando también puede leer de un archivo pasando el nombre como argumento en muchos casos (p.ej.sort < datos.txtes igual asort datos.txt), pero en otros, la única forma es<(p.ej. para responder a un prompt interno de un comando).
Errores comunes y cómo evitarlos:
-
Símbolos mal colocados: Escribir
ls > archivo | grep txtpensando que primero va a filtrar y luego guardar. El orden importa: los redireccionamientos>se aplican al comando que se ejecuta, no al resultado final de toda la pipe. En el ejemplo,ls > archivo | grep txtredirige la salida delsa archivo, dejando a grep sin nada que leer (esperará entrada del pipe pero no llega porquelsya envió todo a archivo en vez de al pipe). Solución: si quieres guardar y filtrar, usateeo redirige el final:ls | grep txt > archivo.txt(así guardas solo lo filtrado). -
Olvidar comillas en grep o find: Cuando usas pipes con grep o find, si el patrón tiene caracteres especiales o espacios, necesitas comillas. Ej:
grep "hola mundo" archivo.txtestá bien.grep hola mundo archivo.txtsin comillas tratará "mundo" como un nombre de archivo a buscar, causando error. Siempre pon entre comillas la cadena de búsqueda a menos que quieras usar regex especial sin comillas (pero eso es avanzado). -
Sobrescribir en lugar de anexar: A veces quieres agregar logs a un file y usas
>por inercia cuando necesitabas>>. Resultado: pierdes lo previo. Si estás haciendo un script que corre repetidamente y guarda resultados, piensa: ¿debo acumular (>>)? ¿o reiniciar cada vez (>)? Elige correctamente. -
No manejar espacios alrededor del pipe/redirección: Debe haber espacio antes y después de
|,>etc. Si escribescmd|other, a veces funciona pero es más seguro siempre separar con espacios:cmd | other. Sin espacios puede no ser interpretado correctamente en ciertos casos. -
Redirigir al mismo archivo que lees: Ej:
sort archivo.txt > archivo.txtes un gran NO. El shell primero vaciaráarchivo.txt(porque va a escribir en él) antes de que sort lo lea, resultado: pierdes el contenido. Siempre que rediriges, asegúrate de no pisar el mismo archivo que usas de entrada. Si necesitas ordenar un archivo "en sitio", usasort archivo -o archivo_sorted.txt(salida a otro) y luego reemplaza manualmente, o emplea-ode sort para escribir a otro archivo.
Tips de rescate si algo falla:
-
Combinar stdout y stderr en pantalla pero no en archivo: A veces quieres ver errores en pantalla pero capturar la salida normal en archivo. Podrías hacer
comando 2>&1 | tee salida.txt– esto manda tanto errores como output al pipe (aparecerán en pantalla por tee y se guardarán en salida.txt). Si quisieras separar luego, es complicado; en esos casos lo mejor es redirigir por separado o usar scripts. Pero saber combinar 2>&1 con tee te da flexibilidad. -
Uso de
xargspara tuberías complejas: Si quieres pasar la salida de un comando como argumentos a otro (y no por STDIN), existexargs. Ej:find . -name "*.txt" | xargs grep "hola"ejecutarágrep "hola"en cada archivo .txt encontrado. Esto es para cuando el segundo comando no lee de STDIN sino espera argumentos (grep en este caso puede leer STDIN también con-Hpero demos la idea).xargses útil, aunque hay alternativas como usar backticks`o$( )(expansión de subshell) para capturar salida como lista de argumentos. -
Redirección here-doc: Mencionando para cultura general, hay redirecciones tipo
<<que permiten proveer múltiples líneas de entrada en el mismo comando (heredoc). Ej:
cat <<EOF > hola.txt
linea1
linea2
EOFEsto crea _hola.txt_ con dos líneas especificadas. Es útil en scripts para generar archivos sin tener que usar echo múltiples veces. No profundizamos en esto aquí, pero es bueno saber que existe.-
Probar comando sin ejecutar (dry-run): Cuando construyes una pipeline compleja, a veces es útil ir probando por partes. Primero ejecuta el primer comando solo para ver qué produce. Luego agrégale el pipe y segundo comando, etc. Así, si algo falla, sabes en qué etapa. Esto previene errores lógicos en encadenamientos largos.
-
Uso de paréntesis subshell vs
{ }: Si necesitas redirigir la salida combinada de varios comandos secuenciales no conectados por pipe, puedes agruparlos. Ej:{ echo "Titulo"; date; uname -r; } > info.txtTodo lo que esté dentro de
{ }se ejecuta en el mismo shell actual con la redirección aplicada a todos (de manera secuencial). Si usas( ), lanza un subshell. Ambas formas te permiten redirigir grupos de comandos juntos. Útil para crear informes que incluyan varias piezas de info en un solo archivo ordenadamente.
Criterios de evaluación del módulo:
✅ El alumno comprende y aplica correctamente la sintaxis de redirección para guardar salidas de comandos en archivos, distinguiendo entre sobrescribir (>) y anexar (>>), y sabe redirigir errores cuando es necesario.
✅ Puede encadenar comandos mediante pipes para filtrar o transformar información, demostrando ingenio para combinar utilidades básicas y lograr resultados útiles (por ejemplo, filtrar procesos, buscar en listas, etc.).
✅ Reconoce cuándo un problema requiere usar un pipeline en vez de una solución manual repetitiva, exhibiendo la filosofía de "construir herramientas con herramientas".
✅ Evita errores comunes al redirigir (como destruir archivos fuente involuntariamente) y muestra precaución al hacerlo, revisando la estructura de su comando antes de ejecutarlo.
✅ Es capaz de explicar en sus palabras qué son STDIN, STDOUT, STDERR, y cómo los redirecciona en diferentes escenarios prácticos.
❓ Preguntas de repaso recomendadas:
-
¿Cómo enviarías la salida de
ls -la un archivo llamado lista.txt y, al mismo tiempo, ver esa salida en pantalla? -
Si un programa imprime mucha información de estado por STDERR que no te interesa, ¿qué harías para ignorarla al ejecutar el programa?
-
Explica qué hace este comando:
dmesg | grep -i error | wc -l. Desglosa cada parte y el resultado final esperado. -
Tienes un archivo entrada.txt con 3 números, uno por línea, y un programa
suma.pyque suma números desde STDIN. ¿Cómo usarías la redirección para pasarle el contenido de entrada.txt al programasuma.py? -
¿Qué diferencia hay entre usar comillas simples ' ' y dobles " " al buscar una frase con grep en una tubería? (Pista: piensa en expansión de variables o caracteres especiales en shell, un tema que tocamos tangencialmente).
Requisitos previos al módulo:
-
Familiaridad con los comandos básicos ya vistos (ls, ps, grep, etc.) para poder utilizarlos en las tuberías de práctica.
-
Conocimiento básico de algún editor de texto o echo/redirección para preparar archivos de prueba (por ejemplo, generar un archivo con números para luego filtrarlo).
-
Este módulo es más conceptual en cuanto a operadores, así que asegúrate de tener un ambiente cómodo para experimentar sin miedo: podrías crear un directorio de laboratorio y algunos archivos de texto de prueba para no afectar archivos reales mientras practicas redirecciones.
-
De ser posible, repasar rápidamente conceptos de módulos 2 y 3, ya que acá los integrarmos (por ejemplo, saber moverte a la carpeta correcta antes de redirigir salida a un archivo, etc.).
Búsqueda de texto dentro de archivos: grep y familia
Concepto desarrollado: Encontrar información relevante dentro de archivos de texto es una tarea cotidiana. grep (Global Regular Expression Print) es la utilidad clásica para buscar patrones de texto en uno o varios archivos. Con grep puedes filtrar líneas que contienen (o que no contienen) cierta cadena o expresión regular. La familia grep incluye variantes como egrep (obsoleto, equivalente a grep -E para usar regex extendidas) y fgrep (obsoleto, ahora grep -F para buscar cadenas fijas sin interpretar regex). Hoy en día, grep con flags adecuadas cubre todos esos casos.
Además de grep, mencionaremos find para búsqueda de archivos en el sistema, aunque su propósito es distinto (find busca archivos por nombre u otros criterios, no contenido).
Pero enfocándonos en grep: es extremadamente poderoso con sus patrones, pero en su forma más básica se usa como grep "cadena" archivo. Esto imprimirá las líneas del archivo que contengan "cadena". Puedes combinarlo con wildcards para buscar en múltiples archivos, e incluso usarlo junto con find para buscar dentro de todos los archivos en un directorio.
Comandos esenciales y sintaxis:
-
grep "texto" archivo.txt: muestra las líneas de archivo.txt que coinciden con "texto". La búsqueda distingue mayúsculas/minúsculas por defecto. -
grep -i "error" /var/log/messages: el flag-iignora case (buscará "error", "Error", "ERROR" todo igual). Útil para términos que podrían capitalizarse. -
grep -R "foo" /etc: busca recursivamente en todos los archivos bajo /etc la palabra "foo".-R(o-r) recorre directorios. Añade-npara que muestre el número de línea donde aparece, y-Hpara que siempre muestre el nombre de archivo antes de la línea (por defecto lo hace si más de un archivo, pero con -H fuerzas que siempre muestre). -
grep -v "localhost" hosts.txt:-vinvierte la selección: muestra líneas que no contienen "localhost". Esto sirve para filtrar fuera cierta info. -
grep -c "ssh" /etc/services:-cmuestra solo el conteo de líneas coincidentes, no las líneas en sí. -
grep -A 3 -B 2 "pattern" archivo: muestra contexto: 3 líneas After (después) y 2 Before (antes) de cada línea coincidente, para entender el entorno donde se encontró el texto. -
Expresiones regulares simples en grep:
-
Por defecto grep usa Basic Regular Expressions. Ej:
grep "^usuario:" /etc/passwdbusca líneas que comiencen (^) con "usuario:". Ogrep "[0-9]\{4\}" filebuscaría cualquier número de 4 dígitos seguidos. -
Con
grep -E(Extended) puedes usar metacaracteres más cómodamente:grep -E "error|fail" archivobusca líneas con "error" o "fail".+,?,{m,n}etc. se usan sin escape en -E. -
grep -Ftrata el patrón como fijo (no regex), útil para buscar literalmente algo que tenga caracteres especiales sin preocuparnos de escaparlos.
-
-
ack, ag, rg, etc.: Nota que existen alternativas modernas a grep enfocadas a código fuente (ack, silver searcher
ag, ripgreprg), que no veremos a detalle, pero si te dedicas a desarrollo/DevOps pueden ser interesantes. Con grep estándar tienes de sobra para empezar.
🧪 Ejercicio práctico paso a paso:
-
Búsqueda simple en un archivo: Crea un archivo de ejemplo o toma alguno existente. Por ejemplo, busca en
/etc/services(lista de puertos) la palabra "ssh":grep "ssh" /etc/services. Verás líneas como "ssh 22/tcp" etc. Intenta congrep -i "SSH" /etc/services(debería dar lo mismo en este caso gracias a -i). -
Buscar en múltiples archivos: Ve a
/etcy ejecutagrep -R "CentOS" .(punto indica el directorio actual). Esto buscará "CentOS" en todos los archivos de /etc. Verás muchos “Permission denied” probablemente en errores porque no puedes leer algunos archivos de root. Para evitarlo, añade2>/dev/null. Por ejemplo:grep -R "CentOS" . 2>/dev/null | wc -lpara contar cuántos archivos mencionan "CentOS". (O usasudo grep -R ...si te interesa realmente y tienes permisos). -
Usar grep con pipes: Ya lo hicimos pero refuerza: ejecuta
dmesg(mensajes del kernel) solo filtrando líneas USB:dmesg | grep -i usb. O filtra tu historial bash:history | grep "sudo"para ver qué comandos has ejecutado con sudo recientemente. -
Contexto con -A/-B: Si tienes el archivo
/var/log/messagesdisponible, intentagrep -B 1 -A 2 "error" /var/log/messages(quizá necesites sudo dependiendo del log). Esto mostraría la línea con "error" junto con 1 línea antes y 2 después, para entender qué pasó antes/después del error. -
grep -v para excluir: Supón que en
ps auxhay muchos procesos root y quieres ver solo los de tu usuario. Puedes hacer:ps aux | grep -v root. Esto listará todos menos las líneas donde aparezca "root". O, si quieres quitar del listado delsciertos archivos, podrías hacerls | grep -v "\.txt$"para ocultar archivos .txt del listado (regex $ indica final de línea). -
Buscar con regex más compleja: Crea un archivo alumnos.txt con contenido ficticio como:
Ana:90 Pedro:75 Luis:100Ahora busca quién tiene calificación de dos dígitos:
grep ":[0-9][0-9]$" alumnos.txt. Este patrón significa “dos dígitos al final de la línea precedidos de dos puntos”. Debería coincidir con 90 y 75 pero no con 100 (que son tres dígitos). Verifica el resultado. -
Usar find para archivos: Cambiando un poco, prueba
find ~ -name "*.txt". Esto te listará todos los archivos .txt en tu home (y subdirectorios). Agrega-type fpara asegurarte que sean archivos normales. Intenta crear un archivo ocultotouch .secreto.txten tu home y corre el find de nuevo; lo encontrará (find no oculta nada a propósito). Experimenta con find con distintos criterios:find /etc -maxdepth 1 -type d(lista solo directorios de primer nivel en /etc), ofind . -type f -size +1M(en el dir actual, archivos mayores a 1 MiB). -
Combinar find con grep (más avanzado): Si quisieras buscar dentro de todos los .conf en /etc alguna palabra, podrías hacer: `find /etc -name ".conf" -type f -exec grep -H "searchterm" {} \;
. Esto para cada archivo encontrado ejecuta grep. Es un uso poderoso de find, pero para casos sencillosgrep -R` ya hace esa combinación internamente (buscar archivos y dentro de ellos).
Puntos clave a recordar:
-
grep es sensible a mayúsculas a menos que especifiques
-i. No olvides ese detalle cuando busques, o usa siempre -i si te da igual el case. -
Siempre pon el patrón entre comillas a menos que sea una palabra sencilla sin espacios ni caracteres especiales. Esto previene que la shell interprete cosas (por ejemplo, si buscas
*o[en tu patrón, sin comillas la shell lo tomará como comodín y no llegará correctamente a grep). -
grep -Res tu amigo para buscar en muchos archivos, pero úsalo con precaución en directorios enormes (comogrep -R "foo" /, que será lento y tirará muchos errores de permisos). Mejor delimita el scope (buscar en /etc, o en ~/mis_proyectos). -
Para buscar patrones más avanzados, aprende regex progresivamente. Por ejemplo, saber usar
^inicio,$fin,.cualquier carácter,*repetición, etc., ampliará muchísimo lo que puedes hacer con grep. Un ejemplo útil:grep -R "^\s*$" archivoencontraría líneas en blanco (^\s*$ = líneas que empiezan y terminan sin caracteres visibles, solo espacios tal vez). Ogrep -R "^[^#]" archivo.confpara encontrar líneas que no comienzan con#(es decir, líneas no comentadas). -
(Imagen sugerida: tal vez una captura o ilustración de uso de grep en terminal resaltando la palabra encontrada en contexto, o un diagrama simple mostrando grep buscando dentro de archivos múltiples. Incluso un pequeño ejemplo de regex en una imagen explicativa. Esto visualmente refuerza cómo grep filtra la información relevante dentro de un mar de texto.)**
-
findcomplementa a grep: grep busca texto dentro de archivos, find busca los archivos en sí según nombre, tamaño, fecha, etc. Muchas veces los usarás juntos: primero find para encontrar archivos de interés, luego grep para inspeccionar contenido relevante en ellos. -
No olvides que grep puede leer de STDIN también, no solo archivos. Es decir, es válido hacer
cat archivo | grep "algo"o simplementegrep "algo" archivo(más eficiente). Ambas vías funcionan. Grep también acepta leer múltiples archivos listados:grep "palabra" archivo1.txt archivo2.txtte dirá en cuál archivo encontró qué.
Errores comunes y cómo evitarlos:
-
No obtener salida y pensar que “no funciona”: Si grep no imprime nada, puede ser que no hubo coincidencias. Puedes verificar el código de retorno con
echo $?inmediatamente después; grep devuelve 0 si encontró algo, 1 si no, 2 si hubo error. Para asegurarte que funciona, prueba un patrón que sabes que está, o usagrep -H . archivopara imprimir todas las líneas (grep con un patrón.= cualquier cosa, mostrará todo). -
Olvidar grep recursivo: Algunos novatos hacen
find . -name "*.log" -exec grep "error" {} \;. Esto funciona, pero es más largo y menos eficiente que simplementegrep -R "error" *.log. Recuerda grep -R en directorios. -
Usar cat innecesariamente con grep: Verás memes de "UUoC" (useless use of cat). Ejemplo:
cat archivo | grep "x"es redundante;grep "x" archivohace lo mismo sin invocarcat. No es que sea gravísimo, pero es bueno aprender lo óptimo. -
No escapar caracteres especiales en patrones: Si buscas un punto
.en texto, en regex el punto es comodín (cualquier carácter). Debes escaparlo:grep "\." archivobuscará un punto real. Similar con?,*,[etc. Si quieres evitar lios, usafgrepogrep -Fpara buscar literalmente la cadena tal cual. -
Buscar texto en archivos binarios: grep puede arrojar resultados “raros” si le aplicas a binarios; a veces muestra la línea “Binary file X matches” en lugar de imprimir basura. Tiene opción
-apara tratar binario como texto, pero generalmente si quieres buscar en binarios, usa otras herramientas (no suele ser el caso, normalmente buscas en logs o código que son texto). -
Rendimiento: Grep es muy rápido en general, pero si buscas en todo un sistema montones de cosas, tardará. Evita ejecutar búsquedas gigantescas innecesariamente, filtra por tipo de archivo con find o limita por directorio. También, grep puede usar hilos con
-mo limitar cuántas coincidencias buscar con-m 1(por ejemplo) para cortar pronto si solo te interesa saber si existe al menos una.
Tips de rescate si algo falla:
-
Comprobar codificación y formato: Si grep no encuentra algo que ves en el archivo, puede ser un tema de codificación (ej. texto en UTF-16 no lo verá grep normal) o de caracteres invisibles (quizá la palabra tiene acento diferente o caracteres especiales). Prueba buscar partes más pequeñas del término, o usar
strings archivosi sospechas que aunque lees texto está en binario. -
Uso de
grep -l: Para rápidamente saber qué archivos contienen algo (sin listar las líneas), usagrep -Rl "patrón" directorio/.-l(L minúscula) hace que solo imprima el nombre del archivo donde encontró, no el contenido. Muy útil cuando tienes cientos de archivos y solo te interesa identificar en cuáles aparece el texto buscado. -
Ripgrep (rg) o The Silver Searcher (ag): Si manejas repositorios de código grandes, herramientas como
rgoagson versiones más rápidas y con ignore de .gitignore, etc., para búsquedas. No es necesario para sysadmin básico, pero sabiendo grep, aprender estas es fácil. Mencionarlo puede ser útil para quien luego quiera optimizar su flujo de trabajo. -
Editar directamente los hallazgos: Una vez encuentras algo con grep, puedes abrir el archivo en esa línea en un editor: por ejemplo con
vim +NUM archivosaltas a la línea NUM. O usarsed -isi es un reemplazo global. Esto es más avanzado, pero muestra hacia dónde se puede ir integrando búsqueda y edición. -
Buscar y reemplazar (sed): Aunque es tema aparte, a menudo después de
grepvienesed(stream editor) para reemplazar texto. Un mini tip:sed -i 's/viejo/nuevo/g' archivo.txtreemplaza "viejo" por "nuevo" en todo el archivo in-situ. Solo hazlo si estás seguro (tal vez respaldar antes). Sed y awk son utilidades potentes que continúan donde grep deja (grep encuentra, sed modifica, awk analiza estructurado). No profundizamos en este curso introductorio, pero ten en mente que existen.
Criterios de evaluación del módulo:
✅ El alumno puede utilizar grep para encontrar texto en archivos simples, aplicar opciones como -i, -v, -R, y entiende cómo buscar patrones básicos, tanto literales como usando algunos metacaracteres regex.
✅ Es capaz de buscar en múltiples archivos o recursivamente en directorios, manejando la salida extensa ya sea contándola, filtrándola o redirigiendo errores de permisos para enfocarse en resultados relevantes.
✅ Integra grep en pipes con otros comandos para refinar resultados (por ejemplo, filtrar la salida de otro comando por una palabra clave), mostrando soltura en combinar herramientas.
✅ Hace uso consciente de find para localizar archivos por nombre u otras propiedades, y sabe diferenciar cuándo usar grep (contenido) vs find (nombre/atributos) para lograr su objetivo de búsqueda.
✅ Conoce las limitaciones de grep (sensible a mayúsculas, necesidades de escapado, rendimiento en búsquedas masivas) y aplica estrategias para evitarlas o mitigarlas.
❓ Preguntas de repaso recomendadas:
-
¿Cómo buscarías todas las líneas que no contienen la palabra "INFO" en un archivo de log?
-
Si tienes una carpeta con archivos de código fuente y quieres encontrar cuál de ellos menciona la función "calculate_sum", ¿qué comando usarías?
-
Explica qué diferencia hay entre usar
grep -R "foo" /homey usarfind /home -type f -exec grep "foo" {} \;. ¿En qué caso preferirías uno u otro? -
Tienes un archivo con texto desordenado y quieres ver todas las líneas que comienzan con un dígito. ¿Cómo lograrías eso con grep?
-
¿Qué hace el siguiente comando?
grep -Hn "main" *.c | grep -v "//". (Pista: Es un uso encadenado para buscar líneas con "main" en archivos C, excluyendo aquellas que parecen comentadas con //).